Publié le 05-04-2022
Avec sa nouvelle mouture du Langage Go, Google nous propose une fonctionnalité intéressante qui espérons le ne passera pas inaperçu. En effet, avec l’arrivée de la version 1.18, Go nous offre un mécanisme de Fuzzing qui s’intègre dans les tests unitaires.
Introduction
Le fuzzing est une technique souvent utilisée par les chercheurs en sécurité pour identifier des vulnérabilités dans un applicatif. Le principe est d’injecter de la donnée aléatoire pour valider qu’aucun comportement inattendu n’apparait lors de l’exécution du programme. Ces éléments aléatoires peuvent être injectés dans des champs textes, des arguments, des fichiers, des périphériques ou n’importe quels éléments contrôlable par l’utilisateur ou extérieur au programme. A l’aide de cette technique il est par exemple possible de détecter la présence de dépassement de mémoire, de race condition ou bien de fuites de mémoire.
A l’aide du fuzzing, les vulnérabilités suivantes ont d’ailleurs été identifiées :
- CVE-2019-16411 : Déni de service ou fuite d’information sur le système de détection d’intrusion Suricata
- CVE-2017-3732 : Fuite d’information sur la bibliothèque OpenSSL
- CVE-2016-6978 : Déni de service ou exécution de code arbitraire via Adobe Reader
- CVE-2015-0061 : Fuite d’information sur Windows et Windows server
Le fuzzing est une technique très proche du Monkey Testing, et se différencie uniquement par la méthode employée. Le fuzzing va envoyer de la donnée aléatoire dans l’ensemble de l’application, là où le monkey testing se concentrera sur l’exécution d’actions aléatoire.
Habituellement, ce type de test peut être effectué avec des fuzzers tels que wfuzz, AFL, ou Burpsuite. Ils se basent souvent sur des dictionnaires ou des mutations et cherchent à identifier des comportements ou résultats inattendu. L’intérêt en dehors d’un aspect uniquement “cybersécurité”, est d’obtenir un résultat non pris en compte dans les tests unitaires classiques et de pouvoir gérer le cas par la suite.
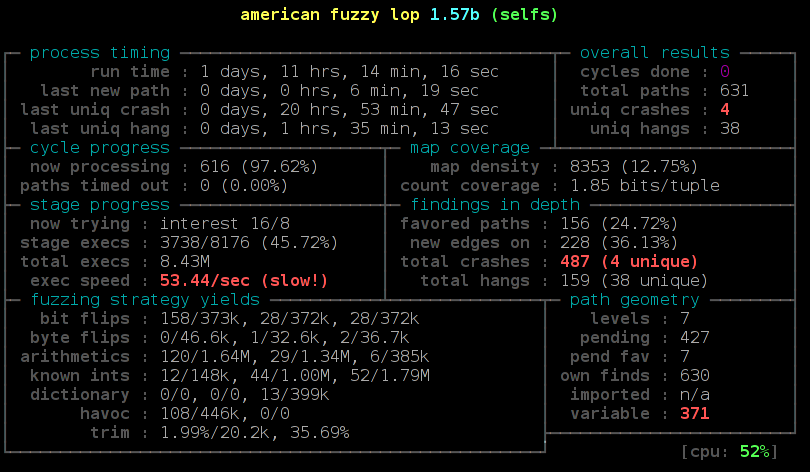
Avec son approche Golang 1.18 permet d’intégrer la recherche de ces bugs directement dans les tests unitaires et donc d’anticiper l’apparition de régression de sécurité entre chaque évolution du code. Quand on a l’habitude de travailler avec de l’intégration continue (CI) comme c’est le cas chez Attineos, ce type de fonctionnalité devient tout de suite une aubaine.
Détecter une injection SQL
Prenons un exemple simple. Notre application est une API qui permet de récupérer une liste de produit depuis une base de données MariaDB/MySQL. Le code de la fonction est le suivant :
func GetProduct(db *sql.DB, id string) *sql.Rows {
query := fmt.Sprintf("SELECT * FROM products WHERE id='%s'", id)
res, err := db.Query(query)
if err != nil {
log.Fatal(err)
}
return res
}
Une analyse rapide du code, nous permet d’identifier une injection SQL juste avant l’exécution de la query. Néanmoins, il est tout à fait possible qu’un développeur passe à côté et ne remarque pas cette vulnérabilité. Sur un test unitaire classique, nous aurions ce type de code :
func TestGetProduct(t *testing.T) {
// We open the database
db := OpenDB()
defer db.Close()
// We prepare our testcases
testcases := []struct {
id string
name string
price float32
}{
{"1", "Pain au chocolat", 0.10},
{"2", "Croissant", 0.80},
{"3", "Pain aux raisins", 0.90},
}
// We try each testcase
for _, tc := range testcases {
// Retrieve the product
row := GetProduct(db, tc.id)
defer row.Close()
// Check that the data retrieved is equals to our testcase
for row.Next() {
var id int
var name string
var price float32
row.Scan(&id, &name, &price)
if name != tc.name {
t.Log("error should be " + tc.name + ", but got " + name)
t.Fail()
}
if price != tc.price {
t.Logf("error should be %f, but got %f", tc.price, price)
t.Fail()
}
}
}
}
Si nous exécutons les tests unitaires, tout se déroule normalement comme attendu :
Il s’agit là d’unes des limites des tests unitaires, car il est compliqué d’écrire un testcase sur un scénario que l’on a pas identifié. Dans le cas présent il s’agit d’une injection SQL qui n’est pas détectée par les testcases que nous avons définis.
C’est dans ce genre de cas que le fuzzing devient intéressant. En créant un nouveau test, nous allons intégrer une dose d’aléatoire dans nos vérifications afin, que cette fois-ci, l’injection SQL soit détectée.
Cette fois-ci notre testcase ne prend pas en argument testing.T mais testing.F. Notre test va donc commencer comme suit :
func FuzzGetProduct(f *testing.F) {
db:= OpenDB()
defer db.Close()
// Our testcase
}
Avant de demander à notre test de lancer son fuzzing, il aura besoin de quelques valeurs valides pour la fonction GetProduct afin d’identifier le type de donnée attendu par la fonction. Nous allons donc lui en fournir quelques-uns :
testcases := []string{"1", "2", "42", "15863060418"}
for _, tc := range testcases {
f.Add(tc)
}
Une fois ces données fournies, nous pouvons entrer dans le vif du sujet avec la routine de fuzzing
f.Fuzz(func(t *testing.T, orig string) {
GetProduct(db, orig)
})
Cette dernière partie est celle qui va venir fuzzer notre fonction GetProduct(). Notre test complet contient le code suivant :
func FuzzGetProduct(f *testing.F) {
db := OpenDB()
defer db.Close()
testcases := []string{"1", "2", "15863060418"}
for _, tc := range testcases {
f.Add(tc)
}
f.Fuzz(func(t *testing.T, orig string) {
GetProduct(db, orig)
})
}
Si nous exécutons notre test à nouveau nous avons le même résultat :
# go test
PASS
ok y0no/fuzz_example 0.004s
Sans arguments supplémentaires golang ne lance pas le fuzzing. Pour cela il est nécessaire d’ajouter l’option -fuzz avec le nom de notre test. Dans notre cas la commande sera go test -fuzz=GetProduct, ce qui nous donne le résultat suivant :
go test -fuzz=GetProduct
fuzz: elapsed: 0s, gathering baseline coverage: 0/3 completed
fuzz: elapsed: 0s, gathering baseline coverage: 3/3 completed, now fuzzing with 4 workers
fuzz: elapsed: 0s, execs: 14 (236/sec), new interesting: 1 (total: 4)
--- FAIL: FuzzGetProduct (0.06s)
fuzzing process hung or terminated unexpectedly: exit status 1
Failing input written to testdata/fuzz/FuzzGetProduct/7bd1b1c4c3d126e40a4f332964108261a47ec776a24b194fa56bdde7f649a336
To re-run:
go test -run=FuzzGetProduct/7bd1b1c4c3d126e40a4f332964108261a47ec776a24b194fa56bdde7f649a336
FAIL
exit status 1
FAIL y0no/fuzz_example 0.066s
Comme nous pouvons le voir cette fois-ci, le test est à l’état FAIL suite à un argument invalide passé à GetProduct. Pour avoir le détail de ce test invalide, il nous suffit d’aller voir le fichier invalide généré :
cat testdata/fuzz/FuzzGetProduct/7bd1b1c4c3d126e40a4f332964108261a47ec776a24b194fa56bdde7f649a336
go test fuzz v1
string("'")
Dans le cas présent, nous voyons que c’est le caractère ' qui pose problème est fait planter le programme. Si nous injectons cette valeur dans la requête SQL, voici ce que nous obtenons :
query := "SELECT * FROM products WHERE id='''"
On voit très rapidement que notre caractère a été interprété comme une fermeture de chaine de caractère et que la fin de notre requête n’est plus valide. Notre injection SQL a bien été détectée cette fois-ci.
Pour corriger le code, nous pouvons passer par une requête préparée avec le code suivant :
func GetProduct(db *sql.DB, id string) *sql.Rows {
res, err := db.Query("SELECT * FROM products WHERE id=?", id)
if err != nil {
log.Fatal(err)
}
return res
}
Si nous rééxecutons le test qui plantait précédemment, on voit qu’il ne nous pose plus de problème :
go test -run=FuzzGetProduct/7bd1b1c4c3d126e40a4f332964108261a47ec776a24b194fa56bdde7f649a336
PASS
ok y0no/fuzz_example 0.003s
Grace à l’ajout du fuzzing dans nos tests nous avons :
- identifié un scénario de test problématique
- Identifié une vulnérabilité de type injection SQL
- Corrigé “salement” l’injection SQL
Intégration continue
Par défaut, lorsque l’on lance les tests avec fuzzing, go envoi des données aléatoires de manière infinie. Dans le cas où l’on démarre ces tests dans un processus d’intégration continue, l’exécution infinie risque de nous poser problème. Pour faire face à cette contrainte, il est possible d’appliquer une option nommée -fuzztime permettant de définir un temps maximal d’exécution du fuzzing. Si le test dépasse ce temps, alors le programme s’arrête en considérant que le test est à l’état SUCCESS.
Par exemple pour tester uniquement trente secondes de fuzzing :
go test -fuzz=GetProduct -fuzztime=10s
Il est donc très simple aujourd’hui d’ajouter une part d’aléatoire dans les tests unitaires d’un projet go avec cette version 1.18. Il serait donc dommage de s’en priver :)